Reading Time: 6 minutes
This post was edited on 09 May 2017 to add some clarity around authenticating with the Strava API.

In 2016 I made a commitment to myself to record every cycle ride I made. As both a leisure cyclist and cycle commuter, I was keen to know how far I rode in a year, what was the accumulated distance of my daily commute, what distance did I cover on my leisure rides. I already recorded my weekend rides in a phone app called Strava, so it was pretty easy to get into the habit of clicking a button on my phone every time I set off on a cycle commute too.
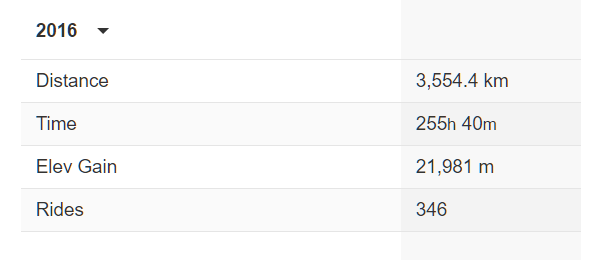
So as we ended 2016, my thoughts turned to what my end of year results would be in Strava. However, as it turned out the data presented to Strava users (shown below) is quite lightweight. It only provides a total distance cycled for the year, and while you can tag a ride as a ‘commute’, nothing is actually done with this data in the Strava interface and the end of year results are not split between commute and non-commute, for example.
Happily, Strava also exposes your personal data through an API. And as a confirmed data geek as well as a keen cyclist, this presented the perfect intersection of both passions! So I set about exploring the Strava API (https://strava.github.io/api/) which it turns out is VERY generous in the data it offers up. I had been playing around with the data science language R during 2016 but this effort had lapsed for the past 6 months, so decided to attempt to extract my Strava data using R as a way of reigniting my learning. And it WAS a learning effort, it seems like lots of Strava libraries have been created for various other programming languages, but very little reusable code was available for R.
Create a Strava application
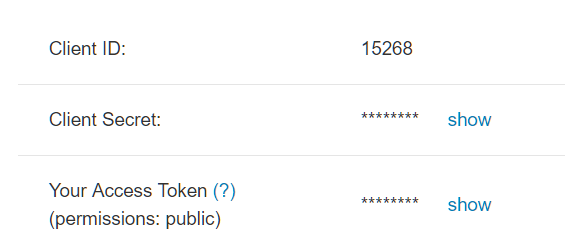
In order to access the Strava API you first need to create a Strava application as a registered Strava user. An overview of Strava’s developer tools is available at http://labs.strava.com/developers but you basically need to access the API settings page at https://www.strava.com/settings/api from where you will be able to retrieve three important pieces of information to reuse later: client ID, secret and access token.
Authenticate with Strava
Strava uses OAuth2 as its authentication protocol. You should be able to follow the steps below to authenticate against your Strava account but, if needed, more detailed instructions on accessing Strava using Oauth2 are found at http://strava.github.io/api/v3/oauth/.
The code needed to access your account is a three-step process.
Firstly you must must create your own application. Using the following code, replace the values “your_strava_athlete_id” with the ‘client ID’ and the “your_strava_secret” with the ‘secret’ from your API Settings page at https://www.strava.com/settings/api:
library(httr)
library(httpuv)
my_app <- oauth_app("strava",
key = "your_strava_athlete_id",
secret = "your_strava_secret"
)
Secondly, you need to describe an OAuth endpoint:
my_endpoint <- oauth_endpoint( request = NULL, authorize = "https://www.strava.com/oauth/authorize", access = "https://www.strava.com/oauth/token" )
Finally, you need to generate an oauth2.0 token. This encapsulates the app, the endpoint and some other parameters. By default the API will only retrieve your ‘public’ activities, so the ‘view_private’ parameter is vital if you want to include activities you marked as Private (when recording my rides I tend to flag my commutes as ‘Private’ so as not to spam my followers’ timelines with my twice-daily short rides!).
sig <- oauth2.0_token(my_endpoint, my_app, scope = "view_private", type = NULL, use_oob = FALSE, as_header = FALSE, use_basic_auth = FALSE, cache = FALSE)
Once this last section is run, your browser will open with the message, “Authentication complete. Please close this page and return to R.” Authentication is now complete and you can go back into RStudio and start to extract your data via the Strava API.
Extract the Strava activity data
The API exposes a tremendous amount of activity data including code snippets that will help you create, retrieve, update and delete activities. This is great for app builders (and there are a LOT of apps integrating with Strava out there!) but my use case is simple: retrieve all my activities for 2016.
The following code gets all your activities and returns them as a list vector. Note that Strava requires your access_token to be sent along with each request. By default, the data returned will paginate at 30 records, but you can use the ‘per_page’ parameter to return up to 200 records, and if needed you can specify the ‘page’ parameter to request further pages.
library(jsonlite)
jsonData <- fromJSON("https://www.strava.com/api/v3/athlete/activities?access_token=<your_strava_access_token>&per_page=200", flatten = TRUE)
You can then run a few checks on the data before retrieving the full set of records.
nrow(jsonData) ##returns the number of records retrieved names(jsonData) ##returns the column names of list vector returned head(jsonData, n=3) ## returns the first three full records
There are 48 columns in total returned, including geographic data which is far more than needed for this simple use case, so using the names(jsonData) we can determine which fields to display in our summary data.
.png)

Then use the ‘c’ function to output a summary list containing just the column id’s of interest.
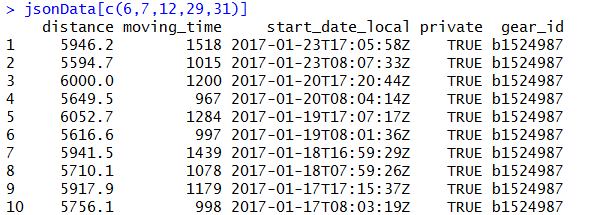
jsonData[c(6,7,12,29,31)]
This returns 200 records, the limit returned by the Strava API, so we actually need to use the ‘page’ parameter to retrieve the additional pages.
jsonData_p2 <- fromJSON("https://www.strava.com/api/v3/athlete/activities?access_token=<your_strava_access_token>&per_page=200&page=2", flatten = TRUE)
jsonData_p2[c(6,7,12,29,31)]
jsonData_p3 <- fromJSON("https://www.strava.com/api/v3/athlete/activities?access_token=<your_strava_access_token>&per_page=200&page=3", flatten = TRUE)
jsonData_p3[c(6,7,12,29,31)]
You could of course write a loop at this point, especially for larger data sets, but we only have a few hundred records in this case. Now that we have three pages of data, these need to be combined into one list, using the rbind.pages function.
alltimeData <- rbind.pages(list(jsonData, jsonData_p2, jsonData_p3)) ##combines the three list vectors into one nrow(alltimeData) ##show your full strava activity count for all time alltimeData[c(6,7,12,29,31)] ##display the summary data for ALL records
Extract the 2016 subset of data
To then extrapolate the 2016 data we can grep the combined list as follows
data2016 <- alltimeData[grep("2016-", alltimeData$start_date), ] ##extract just the 2016 rides
nrow(data2016) ##count the number of records from 2016
data2016[c(5,6,11,27,29)] ## display the summary data of these 2016 rides
We now have the complete list vector for all 2016 rides and can start performing some calculations on this data!
And the answers are…
The reason I did this task in the first place was to calculate my total distance for 2016 and to break this down into total commuting distance (where ‘commute’ = true) and total leisure riding distance (where ‘commute’ = false) in 2016. This is achieved using the following sums:
sum(data2016$distance)/1000 ##total 2016 distance, converted from meters to km sum(data2016[which(data2016[,27]==TRUE),6])/1000 ##total distance where Commute = True, also converted from meters to km sum(data2016[which(data2016[,27]==FALSE),6])/1000 ##total distance where Commute = False, again converted from meters to km
So what distance did I actually cover in 2016?

An overall distance of 3,554 km is the equivalent of riding from Brighton to Cairo, not too shabby an annual distance! I wasn’t expecting my little old daily commute (5k each way) to accumulate more distance than my weekend rides, especially given a few very long 200K+ days out in the saddle last year. It’s good to also now have a benchmark for 2017, plus of course I now have access to a vast treasure trove of Strava data to run further analysis on! Next step… my own dashboard!
Hi ,
I tried to replicate the code however I was stuck at the point where we need to generate Oauth2 token,
This was the erroe message I was getting on the browser
{“message”:”Bad Request”,”errors”:[{“resource”:”Application”,”field”:”client_id”,”code”:”invalid”}]}
Please help
Hi Rahul,
Sorry for the delay responding. I think you copied out the following code without replacing the values for ‘key’ and ‘secret’ with your own.
my_app <- oauth_app("strava",
key = "your_strava_athlete_id",
secret = "your_strava_secret"
)
You need go to http://labs.strava.com/developers/ where you can register a new app and receive your cient ID and secret. If you swap out those in the code snippet above, it should all work!
I will update my post to make this clearer, thanks!
Hi,
thanks for this, very helpful! However, I have one question: I tried pulling my data into databricks, using R.
Importing my activity data works fine, but I only get summarized representations (not a detailed ones).
According to the strava API help:
“Returns a detailed representation if the activity is owned by the requesting athlete. Returns a summary representation for all other requests.”
Fields like ‘description’, ‘laps’,… are therefore not available. How can I retrieve detailed representations of my activities, in other words, how do I tell the Strava API that I AM the requesting athlete?
As a possible answer, since I’m not in visual studio but a browser-interface, the step below does not work(Error : oauth_listener() needs an interactive environment.)
sig <- oauth2.0_token(my_endpoint, my_app, scope = "view_private", type = NULL, use_oob = FALSE, as_header = FALSE, use_basic_auth = FALSE, cache = FALSE)
Any help would be great!
Hi,
I am getting following errors:
Waiting for authentication in browser…
Press Esc/Ctrl + C to abort
Authentication complete.
Error in curl::curl_fetch_memory(url, handle = handle) :
Couldn’t resolve host name
Further while fetching json data, following error is coming:
Error in open.connection(con, “rb”) : Couldn’t resolve host name
Please help.
Hi,
THis is a great tutorial – thank you! I’ve had no trouble getting my data but im wonder if (how) i can access, for instance, the individuals in my riding group. Do you have any advice on that?
Thank you
CH